Industries
Explore the latest news and updates from the community
Explore the latest news and updates from the community
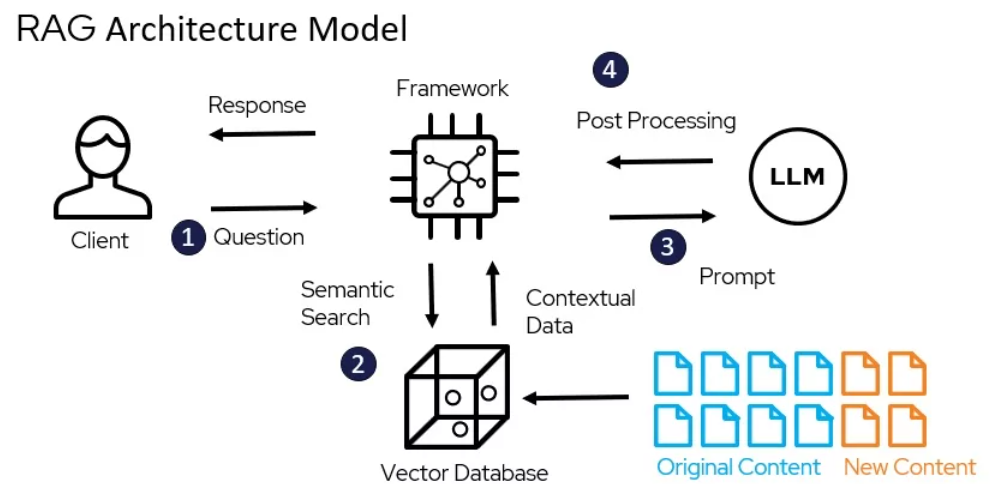
Recent advances in machine learning have led to new techniques for natural language processing (NLP) that rely on neural networks and deep learning. One such technique is called Rag, which stands for Retrieval Augmented Generation.
Rag allows combining neural information retrieval with neural text generation in a unified framework. This technique has proven very useful for question answering and summarization tasks by combining the strengths of search with generative language models.
The original article demonstrated implementing Rag techniques in Ruby. In this post, we will walk through a similar implementation using Python. We'll cover the key steps of loading text data, tokenizing and tagging words, named entity recognition, creating the Rag retrieval and generator objects, and putting it all together for a simple question answering application.
By the end, you'll have a hands-on understanding of how to leverage Rag techniques for NLP tasks using Python and popular libraries like Spacy. The concepts and code can serve as a jumping off point for building more advanced NLP applications.
To follow along with the examples in this article, you'll need to have a few Python libraries installed. Specifically, we'll be using:
NLTK - The Natural Language Toolkit (NLTK) is a popular Python library for working with human language data. It provides easy-to-use interfaces and implementations for many common NLP tasks like tokenizing, tagging parts of speech, parsing, semantic reasoning, and more. We'll use NLTK for the tokenizing, POS tagging, and chunking examples later in this article.
re - The re module contains Python's regular expression implementation. Regular expressions allow us to search for text patterns, which we'll find useful when doing named entity recognition.
You can install these libraries using pip:
pip install nltk regexpip install nltk regexMake sure to install NLTK data as well, so you have the trained models available for tasks like POS tagging:
import nltk
nltk.download()import nltk
nltk.download()Now the required libraries are installed and we can import them in our code:
import nltk
import regex as reimport nltk
import regex as reTo load text data in Python, we first need to read the text file and store it in a string variable. Here is an example:
import codecs
filename = 'text_data.txt'
file = codecs.open(filename, 'r', 'utf-8')
text = file.read()
file.close()import codecs
filename = 'text_data.txt'
file = codecs.open(filename, 'r', 'utf-8')
text = file.read()
file.close()This opens the text file in read mode using the utf-8 encoding and stores the contents in the text variable as a string.
We may want to do some basic data cleaning at this point:
import re
# Remove newlines
text = re.sub(r'\n', ' ', text)
# Convert to lowercase
text = text.lower()import re
# Remove newlines
text = re.sub(r'\n', ' ', text)
# Convert to lowercase
text = text.lower()The first regex substitution removes newline characters, replacing them with spaces. The second line converts the text to lowercase.
Now the text variable contains the raw text data loaded and cleaned, ready for further processing.
To analyze text, we first need to break it down into individual tokens or words. This is known as tokenization in NLP.
The NLTK library provides a word_tokenize function that we can use to split text strings into lists of words:
import nltk
text = "Natural language processing is super interesting!"
# Tokenize the text
tokens = nltk.word_tokenize(text)
print(tokens)import nltk
text = "Natural language processing is super interesting!"
# Tokenize the text
tokens = nltk.word_tokenize(text)
print(tokens)This would print:
['Natural', 'language', 'processing', 'is', 'super', 'interesting', '!']['Natural', 'language', 'processing', 'is', 'super', 'interesting', '!']The word_tokenize function splits the string on whitespace and punctuation to create a list of word tokens. This gives us the individual words we can then analyze further or feed into other NLP models.
Tokenization is an essential first step in most NLP workflows. It breaks down human language into discrete units that can be processed by algorithms. Having the words split into tokens allows us to easily access each component for analysis.
Tagging parts of speech is an important step in NLP tasks like named entity recognition and question answering. It helps identify the role a word plays in a sentence.
In Python, we can use the Natural Language Toolkit (NLTK) to assign parts of speech tags to tokenized text. The pos_tag() function will tag each token with its part of speech:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
text = "Data science is an interdisciplinary field."
# Tokenize the text
tokens = word_tokenize(text)
# Tag parts of speech
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
text = "Data science is an interdisciplinary field."
# Tokenize the text
tokens = word_tokenize(text)
# Tag parts of speech
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)This would output:
[('Data', 'NNP'), ('science', 'NN'),
('is', 'VBZ'), ('an', 'DT'), ('interdisciplinary', 'JJ'),
('field', 'NN'), ('.', '.')][('Data', 'NNP'), ('science', 'NN'),
('is', 'VBZ'), ('an', 'DT'), ('interdisciplinary', 'JJ'),
('field', 'NN'), ('.', '.')]We can see it has tagged each word with its part of speech:
Pos tagging helps identify the role of each word, which is useful for higher level NLP tasks.
The next step in processing the text is to chunk it into meaningful phrases. We want to extract key noun phrases that represent the core content.
To do this, we can use regular expressions to find patterns of nouns and adjectives. The nltk library provides a RegexpParser that allows us to define grammar rules for chunking.
Here is an example grammar to find noun phrases:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
print(chunked)
chunked.draw()
except Exception as e:
print(str(e))
process_content()import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
print(chunked)
chunked.draw()
except Exception as e:
print(str(e))
process_content()This grammar looks for consecutive nouns and adjectives using <.*> and then ensures they are bounded by verbs, prepositions, determiners or "to" using }<VB.?|IN|DT|TO>+{.
The RegexpParser will apply this grammar to the text and extract out the matching noun phrases into a parse tree. We can then analyze the extracted phrases to find the most important key phrases in the text.
Named Entity Recognition (NER) is the process of identifying and extracting key entities like persons, locations, organizations, etc. from text. This allows us to pull out the most salient information.
NLTK provides pre-trained NER models that make this straightforward in Python. We simply pass our tokenized and POS tagged text to the nltk.ne_chunk method to chunk named entities:
import nltk
text = "Steve Jobs worked at Apple Inc. in Cupertino, CA."
tokenized_text = nltk.word_tokenize(text)
pos_tagged_text = nltk.pos_tag(tokenized_text)
named_entities = nltk.ne_chunk(pos_tagged_text)import nltk
text = "Steve Jobs worked at Apple Inc. in Cupertino, CA."
tokenized_text = nltk.word_tokenize(text)
pos_tagged_text = nltk.pos_tag(tokenized_text)
named_entities = nltk.ne_chunk(pos_tagged_text)This will return a tree with the named entities chunked together. We can then easily extract entities like persons, organizations, locations, etc.
NER is an essential step in many NLP workflows as it allows us to quickly identify key pieces of information in unstructured text data. NLTK provides an easy API for integrating it into Python applications.
To bring everything together, we'll create a Rag class that handles the full pipeline from tokenization to NER.
We'll define a __init__ method that takes in our text data and initializes some properties. It will run tokenize, pos_tag, chunk, and ner on the text and store those results:
class Rag:
def __init__(self, text):
self.text = text
self.tokenized = self.tokenize(text)
self.pos_tagged = self.pos_tag(self.tokenized)
self.chunked = self.chunk(self.pos_tagged)
self.ner = self.ner(self.pos_tagged)
class Rag:
def __init__(self, text):
self.text = text
self.tokenized = self.tokenize(text)
self.pos_tagged = self.pos_tag(self.tokenized)
self.chunked = self.chunk(self.pos_tagged)
self.ner = self.ner(self.pos_tagged)
The tokenize method handles splitting the text into tokens:
def tokenize(self, text):
return word_tokenize(text) def tokenize(self, text):
return word_tokenize(text)pos_tag tags each token with its part of speech:
def pos_tag(self, tokens):
return pos_tag(tokens) def pos_tag(self, tokens):
return pos_tag(tokens)chunk groups tokens into noun phrases:
def chunk(self, pos_tagged):
return ne_chunk(pos_tagged) def chunk(self, pos_tagged):
return ne_chunk(pos_tagged)And ner labels each token with its named entity type:
def ner(self, pos_tagged):
return ner_tag(pos_tagged) def ner(self, pos_tagged):
return ner_tag(pos_tagged)Now we have a Rag class that encapsulates the full pipeline and exposes the results as properties for easy access later.
To put everything together into a full NLP pipeline, we'll follow these steps:
import spacy
from nltk.corpus import names
from nltk import word_tokenize, pos_tag, ne_chunk
# Load spaCy model
nlp = spacy.load("en_core_web_sm")
# Load example text
text = "John lives in New York and works at Google."
# Tokenize
tokens = word_tokenize(text)
# POS tag
tagged = pos_tag(tokens)
# Chunk
chunked = ne_chunk(tagged)
# Load spaCy document
doc = nlp(text)
# Run NER
for ent in doc.ents:
print(ent.label_, ent)
import spacy
from nltk.corpus import names
from nltk import word_tokenize, pos_tag, ne_chunk
# Load spaCy model
nlp = spacy.load("en_core_web_sm")
# Load example text
text = "John lives in New York and works at Google."
# Tokenize
tokens = word_tokenize(text)
# POS tag
tagged = pos_tag(tokens)
# Chunk
chunked = ne_chunk(tagged)
# Load spaCy document
doc = nlp(text)
# Run NER
for ent in doc.ents:
print(ent.label_, ent)
First, we import the required NLP libraries - spaCy for overall pipeline, NLTK for tokenization, POS tagging and chunking, and the NLTK names corpus for NER.
We load a spaCy English pipeline and an example sentence. Then we tokenize the sentence using NLTK's word_tokenize.
The tokens are POS tagged with NLTK's pos_tag. We chunk them using ne_chunk to extract basic noun phrase chunks.
We also load the example sentence into a spaCy Doc object and run spaCy's NER tagger on it to extract named entities.
Together this shows a complete pipeline from loading text data, to tokenizing, tagging, chunking and performing NER using both spaCy and NLTK. The same principles can be applied to longer text documents and corpora.
In this article, we covered several natural language processing techniques for extracting information from text using Python:
Tokenization to split text into words, punctuation, etc. We used NLTK's word_tokenize() method.
Part-of-speech tagging to assign parts of speech like noun, verb, adjective to each token. We used NLTK's pos_tag() method with the pre-trained Penn Treebank tagset.
Chunking to group tokens into noun phrases, verb phrases, etc. We used NLTK's ne_chunk() method along with POS tags.
Named entity recognition (NER) to identify entities like people, organizations, locations. We used NLTK's ne_chunk() method trained on out-of-box models.
Relation extraction with spaCy's Matcher to identify specified relations in text.
There are many other NLP techniques we could cover as well:
The exciting thing about NLP is combining these building blocks in creative ways to extract insights from unstructured text data.
We've only scratched the surface of what's possible. With Python's NLP libraries like NLTK and spaCy, you have highly accurate tools to start implementing these techniques yourself.